brownbag-science
File formats
Summary
| Format | Who generates it? | Who reads it? |
|---|---|---|
| FASTQ | sequencers, simulation tools |
mapping tools, QC tools, cleaning tools, taxonomic assignation tools |
| FASTA | assembly tools, gene prediction tools … |
visualization tools, almost all |
| SAM/BAM/BAI | mapping tools, samtools |
visualization tools, variant discovery tools, counting tools |
| BED | annotation tools, bedtools |
visualization tools, variant discovery tools, peak calling tools, counting tools |
| GFF | annotation tools |
visualization tools, variant discovery tools, peak calling tools, RNAseq tools |
| VCF | variant discovery tools |
vcftools, visualization tools, variant discovery tools |
Pipeline
Data obtained from next-generation sequencing data must be processed several times. Most of the processing steps are aimed at extracting only that information needed for a specific down-stream analysis, with redundant entries often discarded. Therefore, specific data formats are often associated with different steps of a data processing pipeline.
Here, we just want to give very brief key descriptions of the file, for elaborate information we will link to external websites. Be aware, that the file name sorting here is alphabetical, not according to their usage within an analysis pipeline that is depicted here:
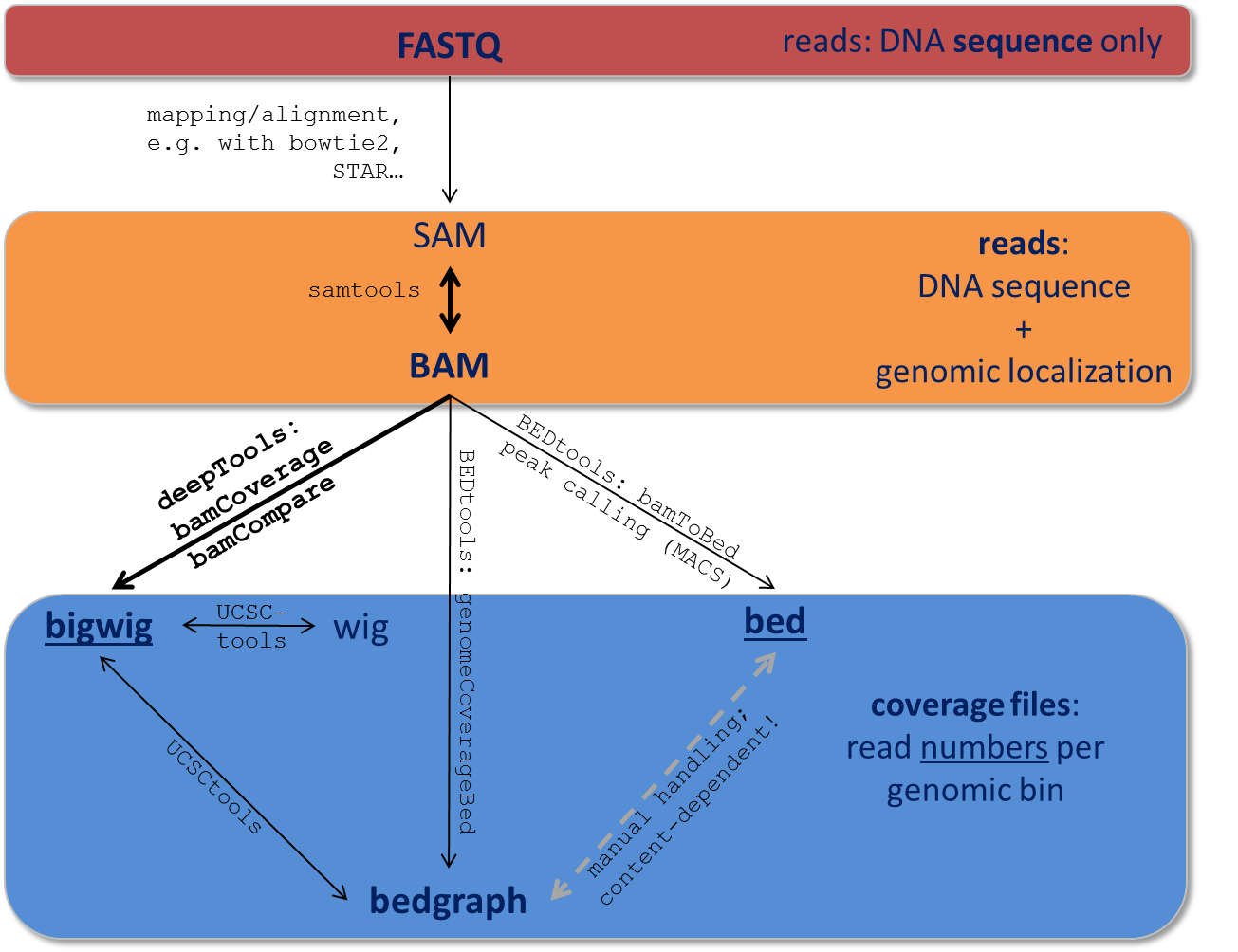
Follow the links for more information on the different tool collections mentioned in the figure:
| samtools | UCSCtools | BEDtools |
NGS file formats
BAM
-
typical file extension:
.bam -
binary file format (complement to SAM)
-
contains information about sequenced reads (typically) after alignment to a reference genome
-
-
each line = 1 mapped read, with information about:
its mapping quality (how likelihood that the reported alignment is correct) its sequencing quality (the probability that each base is correct) its sequence its location in the genome etc.
-
-
highly recommended format for storing data
-
to make a BAM file human-readable, one can, for example, use the program samtools view
- for more information, see below for the definition of SAM files
BED
-
typical file extension:
.bed -
text file
-
used for genomic intervals, e.g. genes, peak regions etc.
-
the format can be found at UCSC
-
for deepTools, the first 3 columns are important: chromosome, start position of the region, end position of the genome
-
do not confuse it with the bedGraph format (although they are related)
-
example lines from a BED file of mouse genes (note that the start position is 0-based, the end-position 1-based, following UCSC conventions for BED files):
chr1 3204562 3661579 NM_001011874 Xkr4 - chr1 4481008 4486494 NM_011441 Sox17 - chr1 4763278 4775807 NM_001177658 Mrpl15 - chr1 4797973 4836816 NM_008866 Lypla1 +
bedGraph
- typical file extension:
.bg,.bedGraph - text file
- similar to BED file (not the same!), it can only contain 4 columns and the 4th column must be a score
- again, read the UCSC description for more details
- 4 example lines from a bedGraph file (like BED files following the UCSC convention, the start position is 0-based, the end-position 1-based in bedGraph files):
chr1 10 20 1.5
chr1 20 30 1.7
chr1 30 40 2.0
chr1 40 50 1.8
bigWig
- typical file extension:
.bw,.bigwig - binary version of a bedGraph or
wigfile - contains coordinates for an interval and an associated score
- the score can be anything, e.g. an average read coverage
- UCSC description for more details
FASTA
Common format for holding sequence data. Wikipedia: FASTA
-
Header line starts with
>, followed by sequence ID; actual sequence follows afterwards - typical file extension:
.fasta - text file, often gzipped (
.fasta.gz) - very simple format for DNA/RNA or protein sequences, this can be anything from small pieces of DNA or proteins to an entire genome (most likely, you will get the genome sequence of your organism of interest in fasta format)
- see the 2bit file format entry for a compressed alternative
seqkit(Shen, Le, Li, and Hu, 2016)- Example sequences
>gi|5524211|gb|AAD44166.1| cytochrome b [Elephas maximus maximus]
LCLYTHIGRNIYYGSYLYSETWNTGIMLLLITMATAFMGYVLPWGQMSFWGATVITNLFSAIPYIGTNLV
EWIWGGFSVDKATLNRFFAFHFILPFTMVALAGVHLTFLHETGSNNPLGLTSDSDKIPFHPYYTIKDFLG
LLILILLLLLLALLSPDMLGDPDNHMPADPLNTPLHIKPEWYFLFAYAILRSVPNKLGGVLALFLSIVIL
GLMPFLHTSKHRSMMLRPLSQALFWTLTMDLLTLTWIGSQPVEYPYTIIGQMASILYFSIILAFLPIAGX
IENY
>Mus_musculus_tRNA-Ala-AGC-1-1 (chr13.trna34-AlaAGC)
GGGGGTGTAGCTCAGTGGTAGAGCGCGTGCTTAGCATGCACGAGGcCCTGGGTTCGATCC
CCAGCACCTCCA
>Mus_musculus_tRNA-Ala-AGC-10-1 (chr13.trna457-AlaAGC)
GGGGGATTAGCTCAAATGGTAGAGCGCTCGCTTAGCATGCAAGAGGtAGTGGGATCGATG
CCCACATCCTCCA
FASTQ
The FASTQ format is the de facto standard used by sequencing instruments; records both sequence and its corresponding quality scores. FASTA with Quality scores. Wikipedia: FASTQ
-
typical file extension:
.fastq,.fq -
text file, often gzipped (–>
.fastq.gz) -
-
contains raw read information – 4 lines per read:
read ID base calls additional information or empty line sequencing quality measures - 1 per base call
-
-
note that there is no information about where in the genome the read originated from
-
example from the wikipedia page, which contains further information:
@read001 # read ID GATTTGGGGTTCAAAGCAGTATCGATCAAATAGTAAATCCATTTGTTCAACTCACAGTTT # read sequence + # usually empty line !''*((((***+))%%%++)(%%%%).1***-+*''))**55CCF>>>>>>CCCCCCC65 # ASCII-encoded quality scores - if you need to find out what type of ASCII-encoding your .fastq file contains, you can simply run FastQC – its summery file will tell you
SAM
The SAM/BAM formats are so-called Sequence Alignment Maps and typically represent the results of aligning a FASTQ file to a reference FASTA file and describe the individual, pairwise alignments that were found. Different algorithms may create different alignments (and hence BAM files)
- typical file extension:
.sam - usually the result of an alignment of sequenced reads to a reference genome
- contains a short header section (entries are marked by @ signs) and an alignment section where each line corresponds to a single read (thus, there can be millions of these lines)
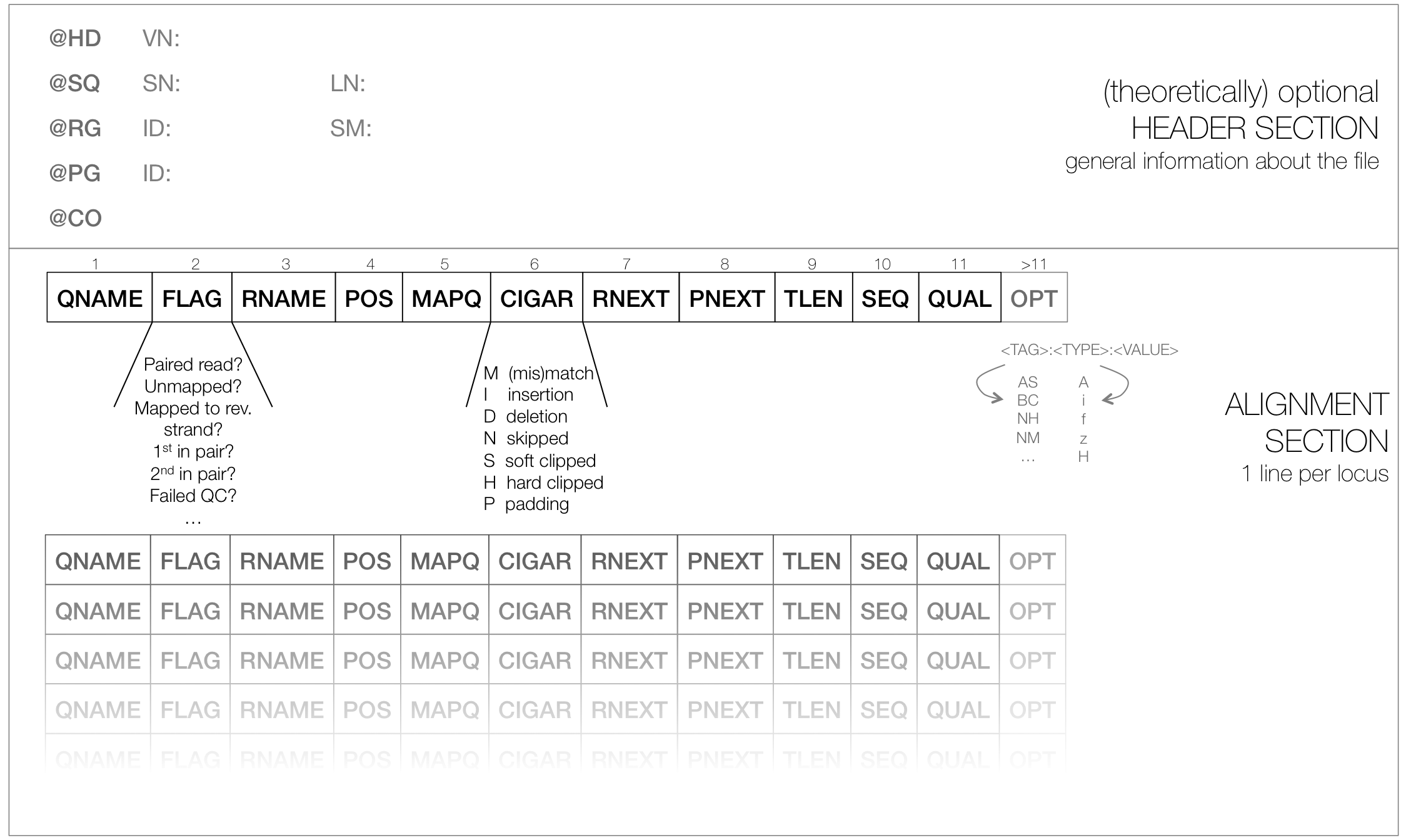
SAM header section
- tab-delimited lines, beginning with @, followed by tag:value pairs
- tag = two-letter string that defines the content and the format of value
SAM alignment section
each line contains information about its mapping quality, its sequence, its location in the genome etc.
r001 163 chr1 7 30 8M2I4M1D3M = 37 39 TTAGATAAAGGATACTG * r002 0 chr1 9 30 3S6M1P1I4M * 0 0 AAAAGATAAGGATA *the flag in the second field contains the answer to several yes/no assessments that are encoded in a single number
for more details on the flag, see this thorough explanation or this more technical explanation
the CIGAR string in the 6th field represents the types of operations that were needed in order to align the read to the specific genome location:
- insertion
- deletion (small deletions denoted with D, bigger deletions, e.g., for spliced reads, denoted with N)
- clipping (deletion at the ends of a read)
SAM Tools
Samtools(Li, Handsaker, Wysoker, Fennell, Ruan, Homer, Marth, Abecasis, and Durbin, 2009) andPicardtools (Broad Institute, 2018) are Swiss-knifes for operating of SAM/BAM formatMultiqQC(Ewels, Magnusson, Lundin, and Käller, 2016) - Aggregate results from bioinformatics analyses across many samples into a single report. (Youtube Intro)
:warning: Warning
Although the SAM/BAM format is rather meticulously defined and documented, whether an alignment program will produce a SAM/BAM file that adheres to these principles is completely up to the programmer. The mapping score, CIGAR string, and particularly, all optional flags (fields >11) are often very differently defined depending on the program. If you plan on filtering your data based on any of these criteria, make sure you know exactly how these entries were calculated and set!
Also See
2bit
- compressed, binary version of genome sequences that are often stored in FASTA
- most genomes in 2bit format can be found at UCSC
- FASTA files can be converted to 2bit using the UCSC programm faToTwoBit, which is available for different platforms at UCSC
- more information can be found here
FastQC
FastQC Andrews, 2010 - QC for (Illumina) FastQ files
BAI
BAM files with Index